Real Solutions to Simplify the Digital Data Flow
by ThoughtSphere
Jan 2025
In today’s digital landscape, clinical trials generate a significant amount of diverse and complex data. Managing this data effectively is crucial for making informed, timely decisions. However, traditional data warehouse approaches often involve navigating cumbersome data structures and rigid frameworks, which stifle data ingestion, slow down data aggregation and delay data operations. By rethinking data flow and harnessing the best that AI and modern data lake technologies have to offer, organizations can revolutionize their digital data processes, reduce operational friction, and drive innovation.
Below we’ll explore four key strategies to simplify the digital data flow, highlighting the importance of leveraging AI, breaking free from traditional data structures, enhancing data accessibility, and embracing a more flexible approach to data updates.
Moving Beyond the Tyranny of SQL and Relational Databases
Traditional relational databases require data to be structured and organized into rigid schemas, which often creates bottlenecks when attempting to integrate various data sources. This structure-centric approach limits flexibility to ingest new, dynamic data sources from wearable devices, but it also fragments the metadata (contextual data) from the clinical data. This greatly hampers the usability of the data and consumes valuable time and resources to separately ingest and re-align metadata to each new data source with a predefined schema.
By adopting a platform with a noSQL database architecture such as ThoughtSphere, organizations can ingest data in any format and of any type. Data can be seamlessly integrated without rigid structures, enabling teams to work with varied data types in their raw forms and to preserve the metadata. This shift allows for greater flexibility and supports rapid ingestion of data from new sources, accelerating the pace of clinical trial operations. Since metadata is never severed, the ThoughtSphere data lake acts as a single source of truth.

Leveraging AI to Pull Data into Organizable Constructs
AI is transforming data management by allowing for seamless ingestion and structuring of data from disparate sources. Instead of manually mapping data to specific formats, AI can automatically recognize and classify incoming data into organizational constructs, reducing the burden on data curators, ETL engineers, and data managers.
With the help of AI-powered tools, such as ThoughtSphere’s ClinHUBTM, teams can streamline data flow right from ingestion. ClinHUB’s AI modeling engine and proprietary algorithms allow for automatic classification and tagging of data, which supports faster, more accurate data preparation and ingestion.
Using AI for Cross-Source Data Pairing for Aggregation and Analysis
Once data is ingested, it must be organized in a way that supports meaningful analysis. AI-driven solutions can automatically detect relationships across datasets and organize them into paired constructs, enabling easy access and aggregation. This cross-source pairing enables data to be readily available for downstream analyses, such as efficacy comparisons, adverse event tracking, and trend identification.
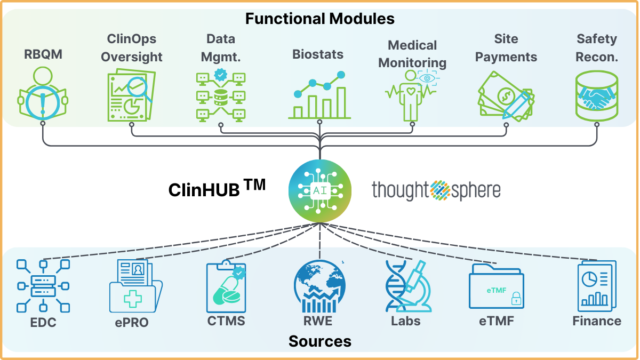
ThoughtSphere’s AI-driven platform, for instance, facilitates cross-source data pairing by leveraging algorithms that recognize and associate related data points, regardless of their original format. This capability simplifies the analysis of integrated data, offering teams a holistic view and supporting better, faster decision-making.
Embracing Data Versioning to Isolate New and Changed Data
Frequent data updates from multiple sources can disrupt workflows, as teams are often forced to reload entire datasets and return to the base data layer. This traditional approach can delay insights and increase the likelihood of errors. By implementing data versioning, organizations can focus on isolating only new or modified data, rather than revisiting & loading the entire dataset each time an update occurs.
With ThoughtSphere’s platform, data versioning is automated, allowing users to pinpoint exactly what has changed. This capability not only reduces the complexity of data updates but also ensures that ongoing analyses remain consistent and that new insights can be generated without having to start from scratch. This approach to data versioning ultimately enhances productivity and maintains data integrity across the clinical trial lifecycle.
Conclusion
Simplifying digital data flow is no longer a luxury but a necessity in today’s clinical landscape. By moving beyond the rigidity of relational databases, leveraging AI to organize data, utilizing cross-source pairing for holistic analysis, and implementing data versioning, organizations can unlock new efficiencies and gain a competitive edge. ThoughtSphere’s platform embodies these principles, providing a flexible, intelligent solution that meets the needs of modern clinical trials and ensures seamless data integration and accessibility.
About ThoughtSphere
At ThoughtSphere our mission is to provide holistic AI-driven data solutions to maximize clinical discoveries and bring effective & safe treatments to patients quicker. We help solve two of the biggest challenges in clinical trials: integrating disparate clinical and operational data and making that data accessible for cross-functional end-users in a collaborative, integrated environment. Want to learn more about our integrated clinical data platform? Visit our website: thoughtsphere.com or request a product demo at sales@thoughtspherewp.test.